| 用文本分析算法探索20个新闻组数据集 – 源码巴士 | 您所在的位置:网站首页 › a bit词性 › 用文本分析算法探索20个新闻组数据集 – 源码巴士 |
用文本分析算法探索20个新闻组数据集 – 源码巴士
|
什么是NLP 20个新闻组数据集,顾名思义,由从新闻文章抽取的文本组成。它是由Ken Lang采集的,广泛用于机器学习技术驱动的文本类应用的实验,尤其是用自然语言处理技术开发文本类应用。 自然语言处理(Natural Language Processing,NLP)是机器学习的一个重要领域,它研究机器(计算机)和人类(自然)语言之间的交互。自然语言不局限于演讲和对话,它们也可以是书面语或符号语言。NLP任务所用的数据形式多样,有社交媒体、网页、医学处方的文本、音频邮件、控制系统的命令,甚至是我们最喜欢的音乐或电影的音频。如今,NLP广泛应用于日常生活:我们的生活离不开机器翻译;天气预报的脚本是自动生成的;我们发现语音搜索很方便;有了智能问答系统,我们可以快速获得问题的答案(比如,加拿大的人口是多少?);语音转文本技术可帮助有特殊需求的学生。 机器若能像人一样,理解语言,我们就可认为它具有智能。1950年,著名的数学家(艾伦•图灵)在题为“Computing Machinery and Intelligence”一文中,提出了一项可以评判机器是否具有智能的测试标准,该标准后被称为图灵测试(Turing test)。它的目标是检验计算机是否能充分理解语言,以至于让人类误以为计算机是一个人。至今,还没有计算机能够通过图灵测试,这一点似乎不足为奇。20世纪50年代,自然语言处理的历史开启了。 理解一门语言也许很困难,但自动将文本从一种语言译为另一种语言是否比较简单一些?我还记得人生的第一堂编程课,实验手册上印有很初级的机器翻译算法。我们能够想象,这种水平的翻译算法,无非是查词典,生成译文。更加可行的方法则是,收集人们已翻译的文本,用它们训练计算机程序。1954年,科学家在Georgetown-IBM实验(乔治城大学和IBM合作的一个项目)中宣称机器翻译将在3~5年内解决。 不幸的是,能够击败翻译员的机器翻译系统至今还没有。但自从引入深度学习方法之后,机器翻译的质量有了大幅提升。 聊天机器人(conversational agent或chatbot)是NLP领域的另一热门话题。计算机能够与人对话这一事实改变了商业的运作方式。2016年,微软公司的人工智能聊天机器人Tay发布,它模仿一个少女,可在Twitter上与用户实时对话。她从用户发表的推文和评论中,学习如何聊天。然而,一波波推文袭来,她招架不住,自动学习了他们的恶言恶语,开始输出不合适的推文到她的主页。她在24小时之内就被关停。 还有一些NLP任务尝试组织知识和概念,从而降低计算机程序操作它们的难度。我们组织和表示概念的方式称为本体论(ontology)。本体定义的是概念与概念间的关系。例如,我们可以用所谓的本体三元组表示两个概念之间的关系,比如Python是一门编程语言。 在NLP的重要应用场景中,比以上使用场景更偏底层的是词性标注。词性(Part Of Speech,POS)是语法意义上单词的类别,比如名词或动词。词性标注尝试确定句子或更长的文档中每个单词的词性。举几个英语单词词性的例子,如表2-1所示。 表2-1 英语单词词性示例 词性 示例 名词(noun) david、machine 代词(pronoun) them、her 形容词(adjective) awesome、amazing 动词(verb) read、write 副词(adverb) very、quite 介词(preposition) out、at 连词(conjunction) and、but 感叹词(interjection) oh[2] 冠词(article) a、the 2.2 强大的Python NLP库之旅介绍了NLP的几种实际应用之后,接下来这一部分将带你一览Python NLP技术栈。这些Python包可处理包括前面提到的几种NLP应用在内的多种NLP任务,比如情感分析、文本分类、命名实体识别等。 用Python编写的、最著名的NLP库有自然语言处理工具集(Natural Language Toolkit,NLTK)、Gensim和TextBlob。sicikit-learn库也提供了NLP的相关功能。NLTK最初是为教育而开发的,如今在业界也被广泛应用。有这样一种说法,不提NLTK,无以言NLP。它是用Python开发NLP应用最著名、也是最为领先的平台之一。我们在终端运行sudo pip install –U nltk命令,即可安装它。 NLTK配备了50多种大型、结构良好的文本数据集,用NLP的术语来讲,它们称为语料库(corpora[3])。语料库可用作检验单词是否出现的词典,也可用作模型学习和训练的数据集。NLTK中一些实用且有趣的语料库介绍如下:Web文本语料库(Web Text Corpus)、Twitter推文数据(Twitter Sample)、莎士比亚作品数据(Shakespeare XML Corpus Sample)、情感极性(Sentiment Polarity)、姓名语料库(Names Corpus,它包含常用名字,稍后我们会使用)、Wordnet和路透社基准语料库(Reuters-21578 benchmark corpus)。NLTK的所有语料库列表请见官网。不论要用哪个语料库的资源,使用之前,我们都得在Python解释器中运行如下脚本来下载语料库: >>> import nltk >>> nltk.download()运行上述命令,将弹出一个新窗口,询问我们要下载哪个包或语料库,如图2-1所示。 我强烈建议你安装整个包,它囊括了本书及以后做研究要用到的所有重要的数据集,大家一般都这么干。安装好之后,我们立马来探索一番它的姓名语料库Names。 首先,导入该语料库:
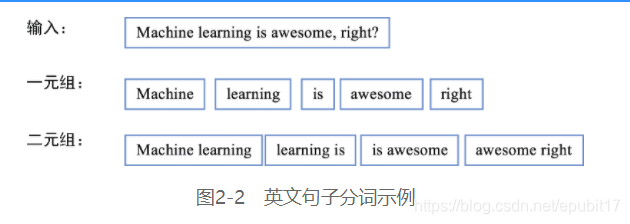
用以下代码输出列表的前10个名字: >>> print names.words()[:10] [u'Abagael', u'Abagail', u'Abbe', u'Abbey', u'Abbi', u'Abbie', u'Abby', u'Abigael', u'Abigail', u'Abigale']共有7944个名字: >>> print len(names.words()) 7944其他语料库也很有趣,同样值得探索。 NLTK除了提供这些易于使用且数据丰富的语料库外,更重要的是它为攻克以下多种NLP和文本分析任务提供了莫大帮助。 分词(tokenization):分词是指将给定文本序列切分为用空格隔开的字符片段,通常还会捎带删除标点、数字和表情符号。分词得到的这些字符片段称为词串(token),留待进一步处理。一个单词组成的词串,在计算语言学中称为一元组(unigram);原文中紧邻的两个单词组成的,称为二元组(bigram);3个连续的单词组成的,称为三元组(trigram);
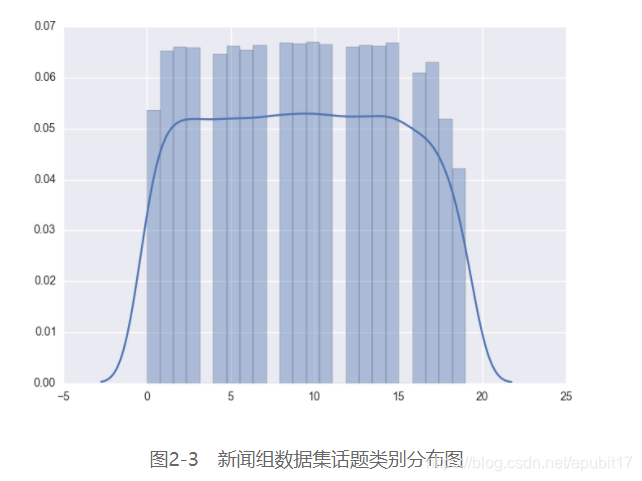
首先,导入3个内置的词干抽取算法中的PorterStemmer(另外两个是LancasterStemmer和SnowballStemmer),并初始化一个词干抽取器: >>> from nltk.stem.porter import PorterStemmer >>> porter_stemmer = PorterStemmer()抽取machine和learning的词干: >>> porter_stemmer.stem('machines') u'machin' >>> porter_stemmer.stem('learning') u'learn'请注意抽取词干时,如有必要的话,抽取器还会将某些字母切去,比如上面的machin就切去了字母e。 现在,导入基于内置的Wordnet语料库实现的词形还原算法,并初始化一个词形还原器: >>> from nltk.stem import WordNetLemmatizer >>> lemmatizer = WordNetLemmatizer()类似地,我们也可以还原machines和learning: >>> lemmatizer.lemmatize('machines') u'machine' >>> lemmatizer.lemmatize('learning') 'learning'为什么经过还原操作之后,learning的词形并未发生变化?原因是该算法默认只还原名词的词形。 Radim Rehurek开发的Gensim库最近几年颇受欢迎。在2008年最初设计时,它的功能是生成给定文章的相似文章列表,它的名字也就是这么来的(Gensim是generate similar的缩写)。后来,Radim Rehurek又大幅改进了它的效率和可扩展性。该库同样可以在终端安装,非常简单,只要运行pip install --upgrade gensim即可。它依赖NumPy和SciPy库,在安装它之前,请确保这两个库已安装。 Gensim以它强大的语义和话题建模算法而出名。话题建模是一种典型的文本挖掘任务,旨在发现文档中的隐语义结构。语义结构说白了就是词语在文档中的分布,显然它是一种无监督学习任务。我们需要输入普通文本,让模型从中找出抽象的话题。 除了强大的语义建模方法外,Gensim还具有以下功能。 相似度查询:检索与给定查询对象相似的对象。词向量化:一种表征词的新方法,可保留词语之间的共现特征。分布式计算:可高效地从百万级文本学习。TextBlob是在NLTK基础上开发的一个相对较新的库。它不仅提供简单易用的内置函数和方法,还封装了常用任务,简化了NLP和文本分析任务。在终端运行pip install –U textblob命令,即可安装TextBlob。 此外,TextBlob还具有目前NLTK所没有的功能,比如拼写检查和纠正以及语言检测和翻译。 虽然最后才讲scikit-learn,但是它也很重要,正如在第一章所讲的,scikit-learn是全书都要用到的主要库。幸运的是,它提供了我们所需的全部文本处理功能(比如分词)和多种机器学习功能。此外,它还内置了20个新闻组数据集的加载器。 我们了解了用什么工具,并正确安装它们之后,那数据又是什么情况呢? 2.3 新闻组数据集本书的第一个项目,我们使用了scikit-learn的20个新闻组数据集。该数据集包括了20个在线新闻组的大约20 000篇文章。新闻组是网上就特定话题展开问答的场所。该数据集已按特定日期,切分成训练集和测试集。 数据集中所有文档为英文。从新闻组的名称即可推断出它们讨论的话题。 其中,一些新闻组紧密相关,甚至重合,比如这5个计算机新闻组(comp.graphics、comp.os.ms-windows.misc、comp.sys.ibm.pc.hardware、comp.sys.mac.hardware和comp.windows.x),而某些新闻组又非常不相关,比如棒球新闻组(rec.sport.baseball)。数据集被做了标注,每篇文档由文本数据和一组标签组成,非常适合有监督学习任务,比如文本分类。我们将在第4章详细介绍有监督学习。现在,我们还是重点介绍无监督学习,从获取数据讲起。 2.4 获取数据从原网站或其他在线仓库手动下载数据集是可以的,只不过该数据集有很多版本,有些做过一定程度的清洗,有些则还是原始数据格式。为了避免混淆,我们最好使用一致的方法来获取该数据集。scikit-learn库提供了一个功能函数,可用该函数来加载该数据集。 下载数据集后,scikit-learn自动将其加载到缓存中,我们无须再次下载。大多数情况下,缓存数据集可视为一种最佳实践,尤其是数据集相对较小的情况。其他Python库也提供下载函数,但并不是都实现了自动缓存功能。这是我们喜欢scikit-learn的另一个原因。 加载该数据集前,先导入该数据集的加载器: >>> from sklearn.datasets import fetch_20newsgroups然后,我们用加载器下载数据集,使用默认参数即可。 >>> groups = fetch_20newsgroups()我们也可以指定一个或多个话题或数据集的某个部分(训练集、测试集或两者都要),也可以只加载数据集的一个子集。加载器函数的所有参数和参数值如表2-2所示。 表2-2 加载器参数介绍 参数 默认参数值 参数值示例 描述 subset train train、test、all 加载训练集、测试集还是加载全部数据集 data_home ~/scikit_learn_data ~/myfiles 数据集存储目录 categories None alt.atheism、sci.space 要加载的新闻组名称列表。默认加载所有新闻组 shuffle True True、False 布尔值,表明是否要打乱数据的顺序 random_state 42 7、43 打乱数据所依据的整型随机种子 remove () header、footers、 quotes 元组,表明省略文章的哪一部分(头、尾和引用)。默认不省略任何部分 download_if_ missing True True、False 布尔值,表明如果在本地未找到数据,是否下载 2.5 思考特征不论用哪一种方式下载,下载了20个新闻组数据集之后,我们就可在程序中用数据对象groups调用数据集了。该数据对象是键值对形式的字典结构,它的键如下所示。 >>> groups.keys() dict_keys(['description', 'target_names', 'target', 'filenames', 'DESCR', 'data'])键target_names给出了20个新闻组的名称: >>> groups['target_names'] ['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']键target为20个新闻组所有文档的话题编号(属于哪个新闻组)列表,话题编号是用整数表示的: >>> groups.target array([7, 4, 4, ..., 3, 1, 8])上述输出结果中共有多少个不同的整数?我们可用NumPy的unique函数找出来: >>> import numpy as np >>> np.unique(groups.target) array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])从0到19,共有20个数,代表20个话题。我们看下第一篇文档的话题编号和对应的新闻组名称: 从以上输出可见,第一篇文档来自rec.autos新闻组,该新闻组的编号为7。阅读该文章,不难看出它是关于汽车的。单词car实际上在文章中出现了好几次。bumper(保险杠)等单词看上去也和汽车相关。然而,doors(门)等单词也许不一定跟汽车有关,它们也可能出现在家居装修或其他话题中。捎带一提,不区分doors、door或同一单词的大小写形式(比如Doors)是有道理的。需要区分大小写的情况很少见,比如我们要找出一篇文档是介绍乐队The Doors,还是介绍门(用木头做的)这一更普通的概念时,则需区分大小写。 我们可以大胆下结论,如想知道一篇文档是否出自rec.autos新闻组,car、doors和bumper这类词的出现与否,是很有帮助的特征。出现或不出现,可用一个布尔型变量来表示,我们也可以考察特定单词的出现次数。例如,car在文档中出现了多次。也许这样的词在文档中出现次数越多,文档与汽车相关的可能性就越大。文档长度不同,特定单词出现次数也存在差异。显然,长文本通常词汇量更大,因而我们还得抵消词汇量大的影响。例如,头两篇文档长度不同: >>> len(groups.data[0]) 721 >>> len(groups.data[1]) 858那么,我们是否应该考虑文档的长度?以我之见,本书页数即使发生变化(在合理范围内),本书也还是与Python和机器学习相关的;因而,文章的长度可能不是一个很显著的特征。 单词序列呢?比如front bumper(前保险杠)、sports car(赛车)和engine specs(发动机类型)这些短语似乎强烈表明文档是以汽车为主题的。然而,car出现的频率比sports car更频繁。并且,二元组的数量比去重后得到的一元组数量多得多。比如,this car和looking car二元组,对新闻组分类而言,二者所拥有的信息量基本相同。显然,一些词的信息量很小。在所有类别的文档中都频繁出现的单词,比如a、the和are称为停用词(stop word),我们应该忽略它们。我们只对特定单词是否出现及其出现次数或其他度量值感兴趣,而不关心单词的出现次序。因而,我们可将文本看作装有若干单词的袋子,这种模型称为词袋模型(bag of words model)。虽然这是一种很基础的模型,但在实际应用中效果不错。我们也可定义更复杂的模型,将单词的次序和词性考虑在内。然而,这类复杂模型计算开销更大,代码实现的难度也很大。基本的词袋模型能满足大多数需求。你不信?我们可尝试绘制一元组的分布图,来看看词袋模型是否好用。 2.6 可视化可视化技术可以展示数据,让用户大致了解数据的结构、发现潜在问题并断明数据是否含有需特殊处理的不规则结构。可视化技术大有裨益。 在多话题或类别分类任务中,明确话题的分布很重要。与类别分布均匀,则最容易处理,因为不存在欠代表或过代表的类别。然而,数据集的分布往往是有倾向的,一个或多个类别会占主导地位。我们用seaborn包计算类别的直方图,并用matplotlib包绘图。两个包都可用pip安装。我们通过以下代码绘制各类别的分布图: >>> import seaborn as sns >>> sns.distplot(groups.target) >>> import matplotlib.pyplot as plt >>> plt.show()上述代码的输出结果如图2-3所示。
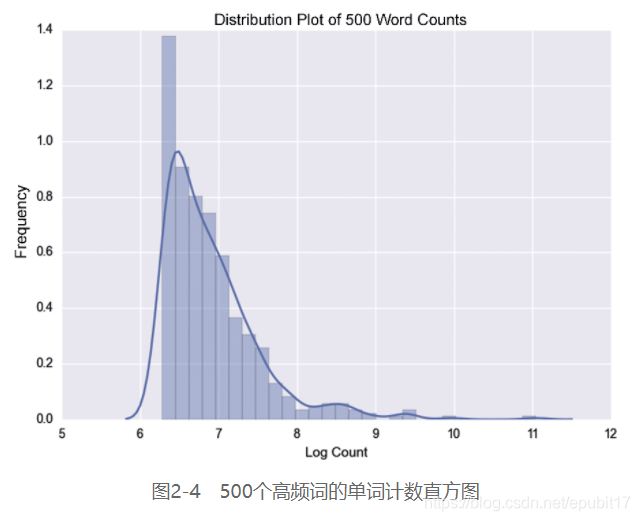
如图2-3所示,各类别(近似)服从均匀分布,我们又少了件担心的事。 20个新闻组数据集的文本数据维度很高。每个特征都得用一维来表示。我们若是用单词计数作为特征,那么感兴趣的特征有多少,维度就有多少。若用一元组计数,那么我们使用CountVectorizer类,它的参数说明请见表2-3。 表2-3 CountVectorizer参数说明 构造器参数 默认参数值 参数值示例 描述 ngram_range (1,1) (1, 2)、(2, 2) 从输入的文本中抽取 stop_words None English、[a, the, of]、None 使用哪个停用词表。若为None,则不过滤停用词 lowercase True True、False 抽取特征时,是否将字母转换为小写 max_features None None、500 若不用None,仅抽取有限数量的特征 binary False True、False 若设为True,所有非零的单词计数都算作1次 我们用下面代码绘制500个高频词的单词计数直方图: >>> from sklearn.feature_extraction.text import CountVectorizer >>> import numpy as np >>> import matplotlib.pyplot as plt >>> import seaborn as sns >>> from sklearn.datasets import fetch_20newsgroups >>> cv = CountVectorizer(stop_words="english", max_features=500) >>> groups = fetch_20newsgroups() >>> transformed = cv.fit_transform(groups.data) >>> print(cv.get_feature_names()) >>> sns.distplot(np.log(transformed.toarray().sum(axis=0))) >>> plt.xlabel('Log Count') >>> plt.ylabel('Frequency') >>> plt.title('Distribution Plot of 500 Word Counts') >>> plt.show()输出结果如图2-4所示。
500个高频词列表如下: ['00', '000', '0d', '0t', '10', '100', '11', '12', '13', '14', '145', '15', '16', '17', '18', '19', '1993', '1d9', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '34u', '35', '40', '45', '50', '55', '80', '92', '93', '__', '___', 'a86', 'able', 'ac', 'access', 'actually', 'address', 'ago', 'agree', 'al', 'american', 'andrew', 'answer', 'anybody', 'apple', 'application', 'apr', 'april', 'area', 'argument', 'armenian', 'armenians', 'article', 'ask', 'asked', 'att', 'au', 'available', 'away', 'ax', 'b8f', 'bad', 'based', 'believe', 'berkeley', 'best', 'better', 'bible', 'big', 'bike', 'bit', 'black', 'board', 'body', 'book', 'box', 'buy', 'ca', 'california', 'called', 'came', 'canada', 'car', 'card', 'care', 'case', 'cause', 'cc', 'center', 'certain', 'certainly', 'change', 'check', 'children', 'chip', 'christ', 'christian', 'christians', 'church', 'city', 'claim', 'clinton', 'clipper', 'cmu', 'code', 'college', 'color', 'colorado', 'columbia', 'com', 'come', 'comes', 'company', 'computer', 'consider', 'contact', 'control', 'copy', 'correct', 'cost', 'country', 'couple', 'course', 'cs', 'current', 'cwru', 'data', 'dave', 'david', 'day', 'days', 'db', 'deal', 'death', 'department', 'dept', 'did', 'didn', 'difference', 'different', 'disk', 'display', 'distribution', 'division', 'dod', 'does', 'doesn', 'doing', 'don', 'dos', 'drive', 'driver', 'drivers', 'earth', 'edu', 'email', 'encryption', 'end', 'engineering', 'especially', 'evidence', 'exactly', 'example', 'experience', 'fact', 'faith', 'faq', 'far', 'fast', 'fax', 'feel', 'file', 'files', 'following', 'free', 'ftp', 'g9v', 'game', 'games', 'general', 'getting', 'given', 'gmt', 'god', 'going', 'good', 'got', 'gov', 'government', 'graphics', 'great', 'group', 'groups', 'guess', 'gun', 'guns', 'hand', 'hard', 'hardware', 'having', 'health', 'heard', 'hell', 'help', 'hi', 'high', 'history', 'hockey', 'home', 'hope', 'host', 'house', 'hp', 'human', 'ibm', 'idea', 'image', 'important', 'include', 'including', 'info', 'information', 'instead', 'institute', 'interested', 'internet', 'isn', 'israel', 'israeli', 'issue', 'james', 'jesus', 'jewish', 'jews', 'jim', 'john', 'just', 'keith', 'key', 'keys', 'keywords', 'kind', 'know', 'known', 'large', 'later', 'law', 'left', 'let', 'level', 'life', 'like', 'likely', 'line', 'lines', 'list', 'little', 'live', 'll', 'local', 'long', 'look', 'looking', 'lot', 'love', 'low', 'ma', 'mac', 'machine', 'mail', 'major', 'make', 'makes', 'making', 'man', 'mark', 'matter', 'max', 'maybe', 'mean', 'means', 'memory', 'men', 'message', 'michael', 'mike', 'mind', 'mit', 'money', 'mr', 'ms', 'na', 'nasa', 'national', 'need', 'net', 'netcom', 'network', 'new', 'news', 'newsreader', 'nice', 'nntp', 'non', 'note', 'number', 'numbers', 'office', 'oh', 'ohio', 'old', 'open', 'opinions', 'order', 'org', 'organization', 'original', 'output', 'package', 'paul', 'pay', 'pc', 'people', 'period', 'person', 'phone', 'pitt', 'pl', 'place', 'play', 'players', 'point', 'points', 'police', 'possible', 'post', 'posting', 'power', 'president', 'press', 'pretty', 'price', 'private', 'probably', 'problem', 'problems', 'program', 'programs', 'provide', 'pub', 'public', 'question', 'questions', 'quite', 'read', 'reading', 'real', 'really', 'reason', 'religion', 'remember', 'reply', 'research', 'right', 'rights', 'robert', 'run', 'running', 'said', 'sale', 'san', 'saw', 'say', 'saying', 'says', 'school', 'science', 'screen', 'scsi', 'season', 'second', 'security', 'seen', 'send', 'sense', 'server', 'service', 'services', 'set', 'similar', 'simple', 'simply', 'single', 'size', 'small', 'software', 'sorry', 'sort', 'sound', 'source', 'space', 'speed', 'st', 'standard', 'start', 'started', 'state', 'states', 'steve', 'stop', 'stuff', 'subject', 'summary', 'sun', 'support', 'sure', 'systems', 'talk', 'talking', 'team', 'technology', 'tell', 'test', 'text', 'thanks', 'thing', 'things', 'think', 'thought', 'time', 'times', 'today', 'told', 'took', 'toronto', 'tried', 'true', 'truth', 'try', 'trying', 'turkish', 'type', 'uiuc', 'uk', 'understand', 'university', 'unix', 'unless', 'usa', 'use', 'used', 'user', 'using', 'usually', 'uucp', 've', 'version', 'video', 'view', 'virginia', 'vs', 'want', 'wanted', 'war', 'washington', 'way', 'went', 'white', 'win', 'window', 'windows', 'won', 'word', 'words', 'work', 'working', 'works', 'world', 'wouldn', 'write', 'writes', 'wrong', 'wrote', 'year', 'years', 'yes', 'york']我们第一次的尝试得到了上面所列的500个高频词词表,我们的目标是找出最具指示意义的特征。但上述列表不够完美。我们能改善它吗?是的,用下节所讲的数据预处理技巧就能改善它。 本文截选自《Python机器学习实战》
1.在讲解算法的原理和用 scikit-learn 库封装好的方法实现算法之前,先通过几个例子,教会你具体的计算方法,让你手动实现算法; 2.书中代码比较连贯,可直接粘贴到Jupyter Notebook中运行,这一点对初学者非常有帮助; 3.书中示例浅显易懂,涵盖多种应用场景:新闻话题分类、垃圾邮件过滤、在线广告点击率预测和股票价格预测等,讲解方式生动有趣; 4.提供源代码。 本书开篇介绍Python语言和机器学习开发环境的搭建方法。后续章节介绍相关的重要概念,比如数据分析、数据预处理、特征抽取、数据可视化、聚类、分类、回归和模型性能度量等。本书包含多个项目案例,涉及几种重要且有趣的机器学习算法,引导读者从头实现自己的模型。学完本书,你将了解机器学习生态系统的全貌,并掌握机器学习技术的实践和应用。 在本书的帮助下,你将学会用强大却很简单的Python语言来处理数据科学难题,并构建自己的解决方案。 本书包括以下内容: ·利用Python语言抽取数据、处理数据和探索数据; ·用Python对多维数据进行可视化,并抽取有用特征; ·深入钻研数据分析技术,正确预测发展趋势; ·用Python从头实现机器学习分类算法和回归算法; ·用雅虎财经数据来分析和预测股价; ·评估并优化机器学习模型的性能; ·用机器学习和Python解决实际问题。 |

【本文地址】